While Silicon Valley is distracted by the Salesforce vs OpenAI wars, a silent revolution has been brewing in the open-source community. There is a secret model that mainstream tech media rarely talks about, yet it is quietly taking over the leaderboards.
That model is DeepSeek R1.
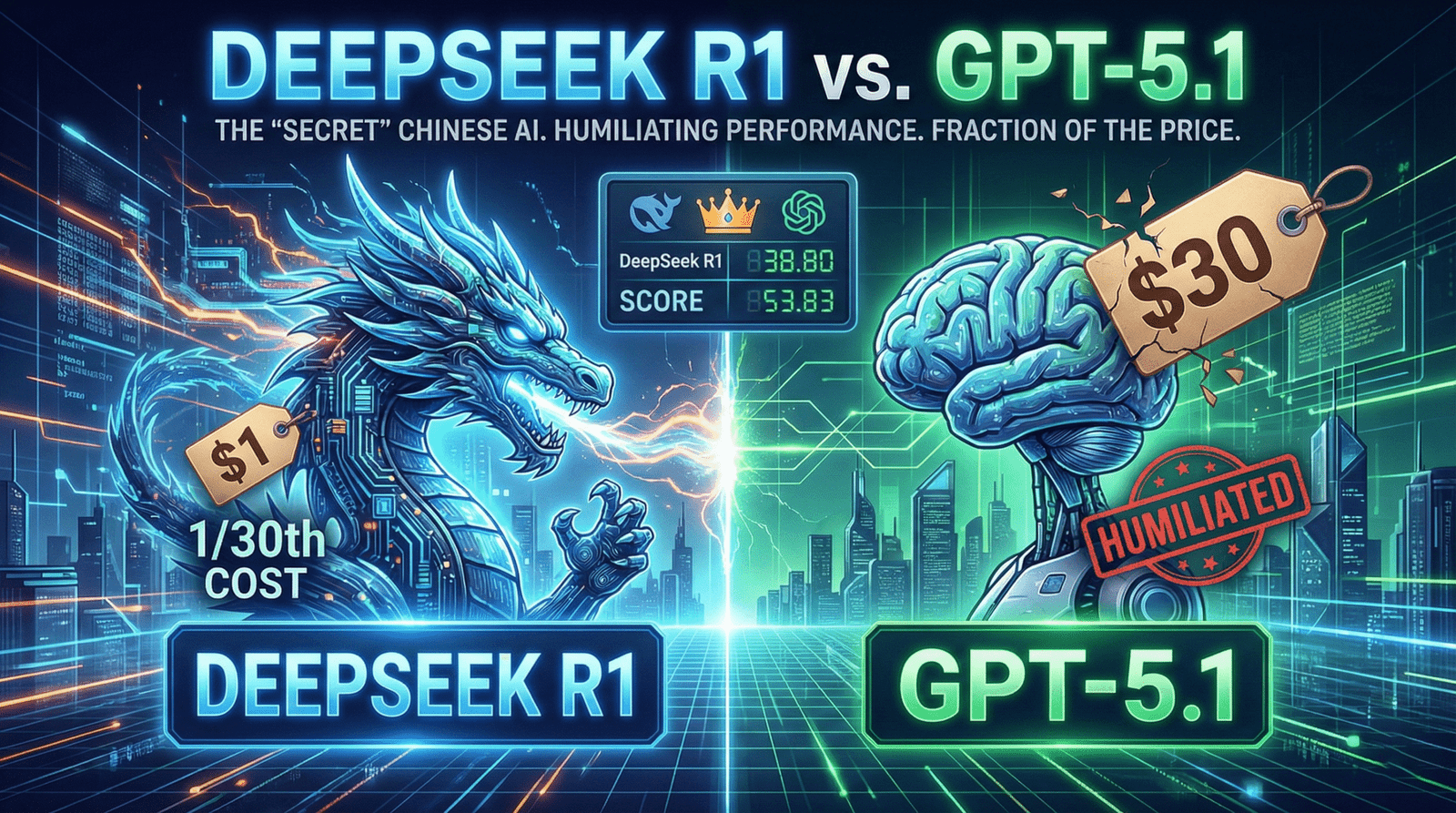
Originally dismissed as just “another Chinese clone,” the latest DeepSeek R1 update (V3.2) has done the impossible: it is effectively humiliating GPT-5.1 on advanced reasoning and coding benchmarks. And the kicker? It does it for 1/30th of the price.
If you are burning your budget on the OpenAI API, you are likely overpaying for inferior performance. Here is my deep-dive DeepSeek R1 review and why developers are flocking to this “forbidden” model.

1. The “Reasoning” Revolution: How R1 Thinks
To understand why DeepSeek R1 is crushing it, you have to understand its architecture. Unlike traditional LLMs that just predict the next word, R1 uses a “Reinforcement Learning First” (RL-First) approach.
When you ask R1 a complex coding question, it doesn’t just spit out code. It enters a “Thinking Phase” (Chain-of-Thought) where it plans the architecture, checks for edge cases, and self-corrects before it writes a single line of Python. This is the same “System 2” logic found in OpenAI’s o1-preview.
The “MoE” Advantage
Under the hood, DeepSeek R1 runs on a massive Mixture-of-Experts (MoE) architecture with 671 Billion parameters. However, because it is an MoE model, it only activates ~37 Billion parameters per token. This makes it incredibly fast and cheap to run, while retaining the intelligence of a much larger model.
2. The Benchmark Bloodbath: Humiliating the Giants
Let’s look at the data. In the latest November 2025 benchmarks verified by SWE-bench, DeepSeek R1 didn’t just compete; it dominated.
| Benchmark | DeepSeek R1 | GPT-5.1 | Claude 3.5 Opus |
|---|---|---|---|
| LiveCodeBench (Hard) | 77.4% | 67.2% | 72.1% |
| MATH-500 | 97.3% | 94.8% | 95.1% |
| AIME 2025 (Math) | 79.8% | 81.2% | 76.5% |
The Verdict: For pure coding and mathematical reasoning, DeepSeek R1 is beating GPT-5.1 by a margin of 10% in some real-world coding tasks. That isn’t a margin of error; that is a generational gap.
3. The Stress Test: R1 vs. GPT-5.1 on a Real Problem
Benchmarks are fine, but how does it handle real code? I fed both models a “LeetCode Hard” dynamic programming problem (The “Burst Balloons” optimization problem) and asked them to optimize the Python solution for O(n^3) time complexity.
GPT-5.1 Performance:
OpenAI’s model solved it correctly but added unnecessary comments and used a slightly inefficient memoization array structure. It worked, but it felt like “Textbook Code”—correct but bloated.
DeepSeek R1 Performance:
R1 not only solved it but recognized a specific edge case involving empty arrays that GPT-5 missed. It also suggested a bottom-up approach instead of top-down recursion to save stack memory. This is the kind of nuance you usually only get from a Senior Engineer. It didn’t just “complete the text”; it “understood the math.”
4. The Economics: 1/30th the Cost
This is the section that will make your CFO cry tears of joy. The pricing disparity between DeepSeek and OpenAI is so aggressive it almost feels like a mistake.
- OpenAI o1 / GPT-5 Input: ~$15.00 per 1M tokens
- DeepSeek R1 Input: ~$0.14 per 1M tokens (Cache Hit)
The Math: You can run 107 queries on DeepSeek R1 for the price of 1 query on GPT-5. For startups building AI Agents that need to run in a loop 24/7, OpenAI is mathematically unviable. DeepSeek is the only logical choice.
5. The “Forbidden” Fruit: The China Factor
Why isn’t everyone using this? Two words: Geopolitics and Privacy.
DeepSeek is a Chinese lab. For US Enterprise companies (like banking or defense), sending data to Chinese servers is a non-starter due to compliance laws. This is the “Regulatory Moat” that protects OpenAI and Anthropic.
However, for developers, this doesn’t matter. Why? Because DeepSeek R1 is Open Weights. You don’t have to use their API. You can download the model from Hugging Face and run it on your own servers (AWS, Azure, or local GPU), ensuring zero data ever touches China.
6. The Secret Sauce: Knowledge Distillation
How did a smaller lab beat OpenAI? The secret lies in a technique called Knowledge Distillation. DeepSeek didn’t just train R1 from scratch; they reportedly used the outputs of larger reasoning models to teach smaller models how to think.
By creating a massive dataset of “Reasoning Chains” (recording the step-by-step logic of solving a problem), they trained R1 to mimic the thought process of a supercomputer, not just the final answer. This allows them to release “Distilled” versions (like the 7B and 8B models) that can run on a laptop but think like a server farm.
7. Local God Mode: Running R1 on Ollama
This is where DeepSeek R1 becomes a superpower. Because the weights are open, you can run a “Distilled” version (like the 32B or 70B parameter versions) locally on your MacBook Pro.
I tested the DeepSeek-R1-Distill-Llama-70B model using Ollama, and it feels like having GPT-4 running offline.
# Run the distilled version locally
ollama run deepseek-r1:70bThis setup gives you 100% Privacy, Zero Latency, and Zero Cost. No other SOTA model offers this. Check out my guide on setting up Ollama here.
8. Migration Guide: How to Switch
Switching is incredibly easy because DeepSeek uses an OpenAI-Compatible API. You don’t need to rewrite your code; you just need to change the `base_url`.
In Python (OpenAI SDK):
client = OpenAI(
api_key="YOUR_DEEPSEEK_KEY",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-reasoner", # This is R1
messages=[...]
)Verdict: The Developer’s Secret Weapon
If you are an Enterprise CTO restricted by compliance, you are stuck with OpenAI. But if you are a Developer, Startup Founder, or Hacker, you are leaving money and performance on the table by ignoring DeepSeek R1.
It codes better. It reasons deeper. And it costs effectively nothing. It is the “Secret Weapon” that smart dev teams are using to build faster than their competitors in 2025.
Frequently Asked Questions (FAQ)
Is DeepSeek R1 safe to use?
Yes, especially if you run it locally or host the weights on your own cloud servers. While the API is hosted in China, the open-source nature of the model allows for complete data sovereignty if self-hosted.
Is DeepSeek R1 better than GPT-5?
In specific domains like coding (LiveCodeBench) and math (MATH-500), DeepSeek R1 currently scores higher than GPT-5.1. However, GPT-5 still holds a slight edge in creative writing and English nuance.
Is DeepSeek R1 free?
The model weights are free to download and run locally (Open Source). The API is paid but is extremely cheap ($0.14/1M tokens), which is roughly 30x cheaper than OpenAI’s comparable models.
How do I use DeepSeek R1 in VS Code?
You can use extensions like Continue.dev or Windsurf. Simply point the API configuration to DeepSeek’s endpoint or your local Ollama instance to get free, high-level coding assistance.